
Jobs
Search Expedia Group Jobs
Amazon DocumentDB Review
Gianluca Della Corte | Systems Architect, Hotels.com in London
Originally published on the Hotels.com Technology blog
On January 9th Amazon announced a new database service called Amazon DocumentDB that they described as a “fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads”.
Is Amazon DocumentDB a real MongoDB?
While offering a MongoDB-compatible API, DocumentDB is not running MongoDB software, but “Amazon DocumentDB emulates the responses that a client expects from a MongoDB server by implementing the Apache 2.0 open source MongoDB 3.6 API” on top of an undisclosed storage engine. From some information, it looks like it is built on top of the Aurora storage subsystem that is also used by both Aurora MySQL and Aurora PostgreSQL. In fact the following features/limitations are common to both DocumentDB and Aurora:
- both replicate six copies of data across three AWS Availability Zones
- both have cluster size limit of 64 TB
- both do not allow null characters (‘\0’ ) in strings
- identifiers are limited to 63 letters for both
- both persist a write-ahead log when writing
- both don’t need to write full buffer page syncs
High Availability
Amazon DocumentDB is designed for 99.99% availability and replicates six copies of your data across three AWS Availability Zones (AZs). DocumentDB availability goal is lower when you have less instances or when it is deployed in less than 3 AZs:
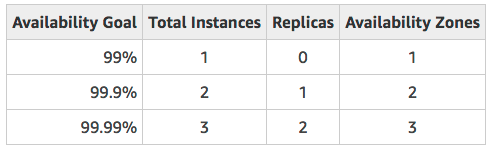
An Amazon DocumentDB cluster consists of two components:
- Cluster volume: cluster has exactly one cluster volume, which can store up to 64 TB of data.
- Instances: provide the processing power for the database, writing data to, and reading data from, the cluster storage volume. An Amazon DocumentDB cluster can have 0–16 instances:
– Primary instance: supports read and write operations and performs all data modifications to the cluster volume. Each Amazon DocumentDB cluster has one primary instance.
– Replica instance: supports only read operations. An Amazon DocumentDB cluster can have up to 15 replicas in addition to the primary instance.

If the primary instance fails, an Amazon DocumentDB replica is promoted to the primary instance. There is a brief interruption during which read and write requests made to the primary instance fail with an exception. Amazon estimates this interruption is less than 120 seconds.
You can customise the order in which replicas are promoted to the primary instance after a failure by assigning each replica a priority, note that it is strongly suggested that replicas should be of the same instance class as the primary. It is also really important to create at least one or more Amazon DocumentDB replicas in two or more different Availability Zones, in this way your datastore can survive a zone failure.
Scalability & Replication
By placing replica instances in separate Availability Zones, it is possible to scale reads and increase cluster availability.
Compute and storage scale independently. It is possible to scale reads by deploying additional replicas. Scalability and storage are scalable up-to 64TB. DocumentDB automatically adds 10GB whenever it reaches capacity.
DocumentDB is also able to automatically fail over to a read replica in the event of a failure–typically in less than 30 seconds. Currently Amazon DocumentDB doesn’t support any kind of multi-region setup.
Amazon DocumentDB does not rely on replicating data to multiple instances to achieve durability, data is durable whether it contains a single instance or 15 instances.
All writes are processed by the primary instance that executes a durable write to the cluster volume. It then replicates the state of that write (not the data) to each active replica. Writes to an Amazon DocumentDB cluster are atomic within a single document.
Consistency
Reads from Amazon DocumentDB replicas are eventually consistent with minimal replica lag (AWS says usually less than 100 milliseconds) after the primary instance writes the data:
- reads from an Amazon DocumentDB cluster’s primary instance have read-after-write consistency
- reads from a read replica have eventual consistency
It is possible to modify the read consistency level by specifying the read preference for the request or connection (it supports all MongoDB read preferences):
- primary: reads are always routed to the primary instance
- primaryPreferred: routes reads to the primary instance under normal operation, in case of failover a replica is used
- secondary: reads are only routed to a replica, never the primary instance
- secondaryPreferred: reads are routed to a read replica when one or more replicas are active. If there are no active replica instances in a cluster, the read request is routed to the primary instance
- nearest: read preference routes reads based solely on the measured latency between the client and all instances in the Amazon DocumentDB cluster
Operations
It is possible to create an AWS DocumentDB cluster using CloudFormation stack (as described here).
Amazon DocumentDB is a fully managed solution that provides the following features:
- auto scaling storage (up to 64 TB in 10GB increments)
- simple compute resource scaling (resources allocated to an instance can be modified by changing instance class)
- built-in monitoring, fault detection, and failover
- daily snapshots
AWS DocumentDB vs AWS ElasticSearch
DocumentDB and ElasticSearch have a lot of features in common, in fact you could even use ElasticSearch as a primary datastore. Some of the features they have in common are:
- document oriented store
- schema-free
- distributed data storage
- high-availability
- replication
However, they come from 2 different database families and are made for different purposes. DocumentDB is a document store while ElasticSearch is a search engine.
Here are some key differences between the two:
- Indexing — ElasticSearch uses Apache Lucene for indexing while MongoDB indexes are based on traditional B+ Tree. Real-time indexing and searching power of ElasticSearch comes from Lucene, which allows creation of indexes on every field of a document by default. In MongoDB, we have to define the index, which improves query performance, but affects write operations.
- Writing — ElasticSearch is slower on adding new data. In ElasticSearch indexing semantics are defined on client side. Indexing cannot be optimised as well as with DocumentDB.
In practice, ElasticSearch is often used together with NoSQL and SQL databases. A datastore is used as persistent storage and source of truth, and ElasticSearch is used for doing complex search queries.
Another key consideration while evaluating DocumentDB vs ElasticSearch is the effort/complexity associated with an ElasticSearch domains definition, sizing and maintenance. It is not so straightforward to do it (in fact it is hard to correctly size storage, shards and instance size). AWS provides some good guidelines, but it is more complex than working with DocumentDB which doesn’t require these considerations.
Hotels.com Architecture team’s advice
Currently in Hotels.com we use many different datastores/search engines, so it is good to summarise our advice on when Amazon DocumentDB is or is not a good option.
Amazon DocumentDB is a good solution when you need to store unstructured data that doesn’t require too many indexes or complex search features.
A good benefit is that you don’t need to care too much about queries upfront. This is particularly useful when you are not the owner/producer of the data you are storing, so you don’t need to adapt your schema to a possible new data structure (like you must do with a SQL database like Amazon Aurora) and you can query data also using new fields (thing that you cannot easily do using another NoSQL solution like Amazon DynamoDB, where your data schema is based on your queries).
It is also a good solution when you don’t need rich indexing capabilities and complex/fast search support (ranked results, full text search with partial matching without using regex, complex geospatial queries with inclusion/exclusion). For these kind of scenarios Amazon ElasticSearch is a better choice.
Currently Amazon DocumentDB has two big drawbacks:
- no multi-region support
- just provisioned mode (not available in serverless mode)
References
- https://aws.amazon.com/blogs/aws/new-amazon-documentdb-with-mongodb-compatibility-fast-scalable-and-highly-available/
- https://aws.amazon.com/documentdb/
- https://aws.amazon.com/documentdb/pricing/
- https://www.infoq.com/news/2019/01/aws-documentdb-mongodb
- https://aws.amazon.com/blogs/database/introducing-the-aurora-storage-engine/
- https://docs.aws.amazon.com/documentdb/latest/developerguide/quick-start-with-cloud-formation.html
- https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/what-is-amazon-elasticsearch-service.html
- https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/sizing-domains.html